Transformer
GPT를 포함한 현재 널리 사용되는 LLM 구조는 모두 Transformer 구조입니다. Transformer는 2017년 구글이 발표한 "Attention is all Need" 논문에서 처음 소개된 딥러닝 모델입니다.
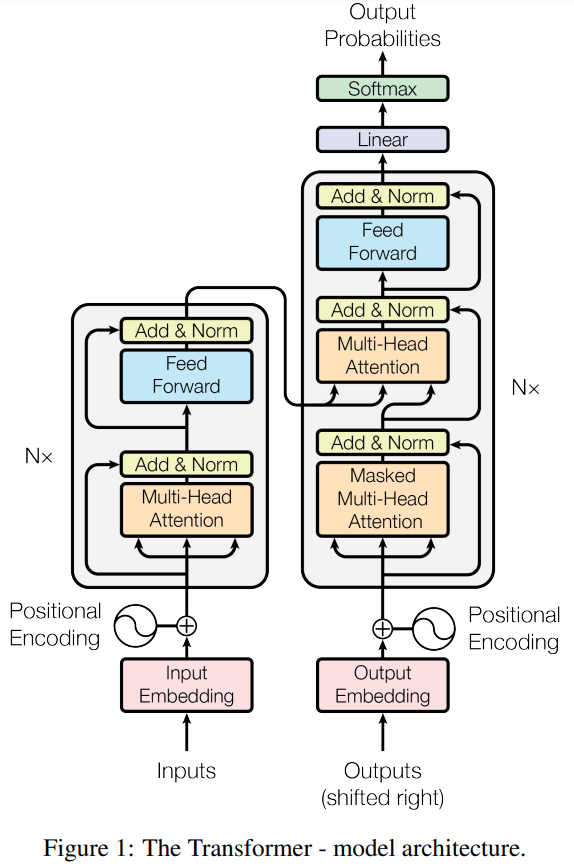
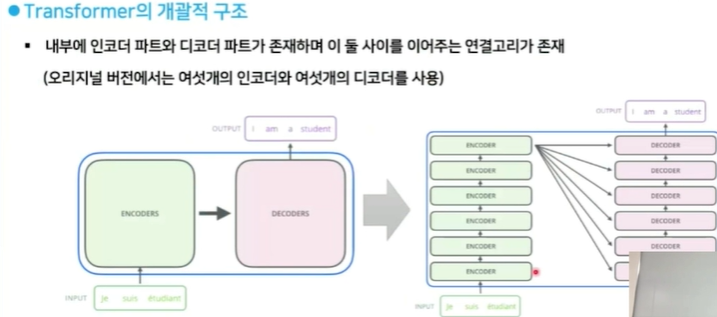
내부에 인코더 파트와 디코더 파트가 존재하고, 이 둘 사이를 이어주는 연결고리가 존재합니다. 쉽게 설명하면, 왼쪽 부분인 인코더는 컴퓨터가 이해할 수 있도록 해주고, 오른쪽 부분인 디코더에서 사람이 잘 이해할 수 있는 답변을 생성해주는 구조입니다. 이런 인코더와 디코더를 연결하는 것이 Attention 메커니즘이라 합니다.
기존 모델 대비 장점
Transformer는 기존 딥러닝 모델들의 근본적인 한계를 해결했습니다.
학습 속도 혁신 (vs RNN/LSTM)
RNN/LSTM은 단어를 순차적으로 처리해야 해서 병렬화가 불가능했습니다. 반면 Transformer는 모든 단어를 동시에 처리할 수 있어 학습 시간이 기존 대비 1/4 수준으로 단축되었습니다.
장거리 의존성 학습 (vs CNN)
CNN은 커널 크기 제한으로 멀리 떨어진 단어 간 관계를 파악하기 어려웠습니다. Transformer는 Self-Attention을 통해 문장 내 모든 단어 간 직접 연결이 가능해, 장거리 의존성을 효과적으로 학습할 수 있습니다.
| 모델 유형 | 연산 복잡도 | 병렬화 | 장거리 의존성 경로 |
| RNN | O(n×d²) | 불가능(O(n)) | O(n) |
| CNN | O(k×n×d²) | 가능 O(1) | O(log(n)) |
| Transformer | O(n²×d) | 가능(O(1)) | O(1) |
Transformer 파생 모델
BERT(Bidirectional Encoder Regresentations from Transformer) (2018.10)
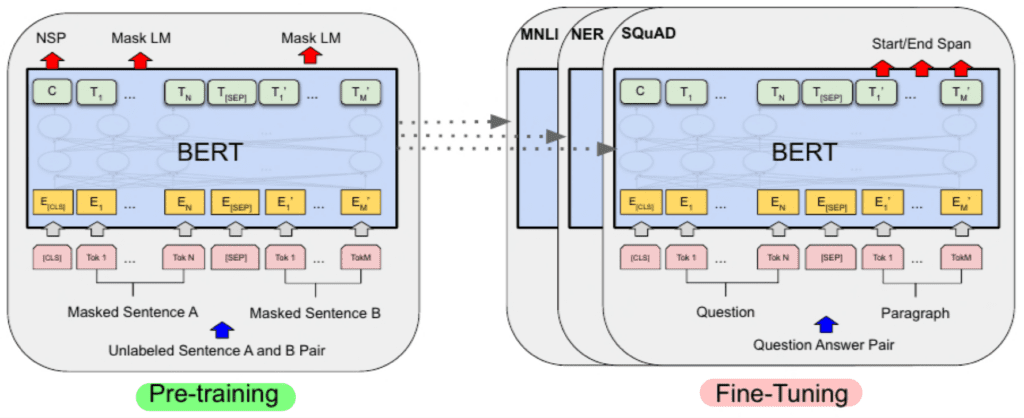
Transformer의 인코더 구조만 사용하는 모델입니다. BERT의 핵심은 문장에서 단어를 지우고 맞추게 하는 학습 방식입니다.(Masked Language Model) 예를들어 "나는 오늘 학교에 갔다"라는 원본 문장이 있을 때, "나는 ___ 학교에 갔다"에서 모델이 "오늘"을 예측하도록 훈련을 하는 것입니다.이는 앞뒤 문맥을 모두 고려해야 합니다. 또한, BERT는 두 문장의 연결 관계도 학습합니다. 이를 통해 더 긴 문장이나 문단의 맥락도 이해할 수 있습니다. BERT는 문장 생성이 아닌 문장 이해에 특화된 모델입니다.
BART(Bidirectional Auto-Regressive Transformer) (2019.10)

BERT가 문장을 잘 표현하는 임베딩 벡터를 추출하는 모델이라면 BART는 인간이 잘 이해할 수 있는 문장을 생성하는 모델입니다. 영어를 넣으면 한국어를 생성하는 기계 번역 등을 할 수 있습니다. 주요 특징으로는 Self-Supervised Learning을 한다는 것입니다. 디코더는 자가회귀(Auto-Regressive) 방식으로 순차적으로 단어를 생성합니다. 학습 시에는 정답 문장과 비교하며 학습하고(Teacher Forcing), 추론 시에는 자신이 생성한 단어를 다음 입력으로 사용합니다.
T5 (Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer) (2019.10)

모든 언어 문제(번역, 요약 등)를 text-to-text-format으로 변환하는 통합된 프레임워크입니다. Original Transformer의 구조를 그대로 따릅니다.
GPT-1 (Generative Pre-Training of a Language Model) (2018.06)
비지도 학습 기반으로 사전 학습한 모델입니다. BERT와는 반대로 디코더만 사용한 모델입니다.
GPT-2 (2019.02)
Fine-Tuning 없이 zero-shot으로 downstream task를 풀 수 있을까에서 나온 모델입니다. 따라서 GPT-1과 동일하지만, 구조를 확장시키고 더 많은 데이터를 학습한 모델입니다. 이때까지도 성능이 뛰어나진 않았습니다.
GPT-3 (2020.05)
Few-Shot 모델입니다. 좋은 모델은 몇 개의 예제만 봐도 잘 추론할 수 있어야 한다는 개념에서 출발했습니다. 예를들어 "영어: Hello / 한국어: 안녕하세요", "영어: Thank you / 한국어: 감사합니다"라는 두 개의 예시만 보여주면, "영어: Good morning"을 입력했을 때 "좋은 아침입니다"라고 답할 수 있습니다. GPT-2보다 훨씬 성능이 좋아졌지만, 대표적으로 이루다 사건처럼 유해한 텍스트를 생성하는 문제가 발생했습니다.
InstructGPT (2022.03)
GPT-3의 유해 텍스트 생성 문제를 해결하기 위해 나온 모델입니다. 핵심은 사람의 피드백을 통해 학습하는 RLHF(Reinforcement Learning with Human Feedback)입니다. 사용자가 "불쾌한 내용을 생성해줘"라고 요청하면 GPT-3는 그대로 생성했지만, InstructGPT는 "죄송합니다. 그런 내용은 생성할 수 없습니다"라고 거절합니다. 사람이 좋은 응답과 나쁜 응답을 평가하고, 이 평가 데이터를 통해 모델을 학습시킵니다. 이러한 방식으로 유해 콘텐츠 생성을 줄이고, 사용자 의도에 맞는 더 도움이 되는 답변을 생성할 수 있게 되었습니다. InstructGPT는 ChatGPT의 기반 기술입니다.
GPT-4 (2023.03)
텍스트뿐만 아니라 이미지도 입력으로 받을 수 있는 멀티모달 버전입니다. 예를들어 냉장고 내부 사진을 보여주고 "이 재료로 뭘 만들 수 있어?"라고 물으면, "사진을 보니 계란, 우유, 치즈가 있네요. 치즈 오믈렛이나 스크램블 에그를 만들 수 있습니다"와 같이 답변합니다. GPT-3.5 버전보다 더 긴 문맥을 이해할 수 있고(최대 32K 토큰), 더 정확한 추론이 가능합니다. 비전 정보를 포함한 복잡한 작업도 처리할 수 있게 되었습니다.
RAG (Retrieval-Augmented Generarion)

Retriever와 Generator로 구성된 모델입니다. Retriever는 질문과 관련된 자료를 찾아주고, Generator는 찾은 자료를 바탕으로 답변을 생성합니다. 예를들어 제네레이터를 학생이라고 하면, 리트리버는 교과서에서 관련된 내용을 찾아주는 역할입니다. 학생은 리트리버가 찾아준 교과서 내용과 질문을 함께 보고 답변을 생성합니다. 이를 통해 모델이 학습하지 않은 최신 정보나 특정 도메인 지식에 대해서도 정확한 답변을 할 수 있습니다.
'컴퓨터 과학(CS) > AI' 카테고리의 다른 글
| FastMCP로 간단하게 만드는 MCP 서버 - 날씨 & 명언 서비스 (0) | 2025.11.05 |
|---|---|
| MCP(Model Context Protocol) (0) | 2025.11.04 |
| 데이터 품질 관리 (2) | 2025.10.20 |
| 좋은 데이터와 나쁜 데이터 (0) | 2025.10.20 |
| Model-Centric AI, Data-Centric AI (0) | 2025.10.20 |

