2000년 초반부터 2023년까지 생산한 데이터의 양이 90ZB(제타바이트)에 달한다고 합니다. 이는 그 이전 5000년간 인류가 쌓은 데이터의 3000배가 넘는 수치입니다. 1인당 일주일에 1TB 용량의 데이터를 생성하는 것과 같은 상황입니다. 이렇게 폭발적으로 증가하는 데이터를 갖고 좋은 AI 시스템을 만들기 위해서는 데이터의 품질에 대해 정의하고 평가하는 기준이 있어야 합니다. 즉, AI 모델이 학습하기에 얼마나 완전하고 정확하게 구축되어 있는지를 파악해야 합니다.
데이터의 품질이란?
AI 모델이 학습하기에 적절한 데이터의 완전성과 정확성을 의미합니다. 즉, 얼마나 일관되고, 오류가 없으며, 필요한 정보를 충분히 담고 있는가로 평가됩니다. 데이터 유형(정형, 비정형)에 따라 다르지만, 일반적인 데이터 품질 기준의 정의는 다음과 같습니다.
| 품질 기준 | 정의 |
| 완전성 (Completeness) | 필수 항목에 누락이 없어야 함 |
| 유일성 (Uniqueness) | 데이터 항목은 유일해야 하며, 중복되어서는 안 됨 |
| 유효성 (Validity) | 데이터 항목은 정해진 데이터 유효 범위 및 도메인을 충족해야 함 |
| 일관성 (Consistency) | 데이터가 지켜야 할 구조, 표현되는 형태가 일관되게 정의되고, 일치해야 함 |
| 정확성 (Accuracy) | 실세계에 존재하는 객체의 표현 값이 정확히 반영되어야 함 |
완전성
| 세부 품질 기준 | 품질 기준 설명 | 활용 예시 |
| 개별 완전성 | 필수 컬럼에는 누락 값이 없어야 함 | 고객의 아이디는 NULL일 수 없음 |
| 조건 유일성 | 조건에 따라 컬럼 값이 항상 존재해야 함 | 기업 고객의 등록번호가 NULL일 수 없음 |
완전성이 지켜지지 않은 경우에는 AI 모델이 학습할 수 있는 정보가 줄어들고 중요한 정보가 손실될 수 있습니다.
유일성
| 세부 품질 기준 | 품질 기준 설명 | 활용 예시 |
| 단독 유일성 | 컬럼은 유일한 값을 가져야 함 | 고객의 이메일 주소는 유일하게 존재 |
| 조건 유일성 | 조건에 따른 값은 유일함 | 강의 시작일에 강의실 코드, 강사 코드가 모두 동일한 값은 유일하게 존재함 |
유일성이 지켜지지 않은 경우에는 중복된 특정 패턴을 과대평가하여 불균형한 모델이 만들어 질 수 있고, 불필요한 학습과 연산 자원 추가로 인한 낭비로 이어집니다.
유효성
| 세부 품질 기준 | 품질 기준 설명 | 활용 예시 |
| 범위 유효성 | 값이 주어진 범위 내 존재해야 함 | 수능 시험의 점수는 0 이상 100 이하의 값 |
| 날짜 유효성 | 날짜 유형은 유효한 날짜 값을 가져야 함 | 20251032는 유효하지 않은 값 |
| 형식 유효성 | 정해진 형식과 일치하는 값을 가져야 함 | 이메일 형식은 xxx@xxx의 형식 |
유효성이 지켜지지 않은 경우에는 비현실적인 결과를 출력할 수 있습니다.(ex. 기대수명 330세 등)
일관성
| 세부 품질 기준 | 품질 기준 설명 | 활용 예시 |
| 포맷 일관성 | 동일 유형의 값은 형식이 일치해야 함 | 날짜는 YYYYMMDD 형식으로 통일 |
| 참조 무결성 | 여러 값이 참조 관계에 있으면 그 무결성을 유지해야 함 | 대출 번호는 대출 상세 내역에 존재해야 함 |
| 데이터 흐름 일관성 | 데이터를 생성하거나 가공하여 이동하는 경우, 연관된 데이터는 모두 일치해야 함 | 현재 가입 고객 수와 DW의 고객 수는 일치해야 함 |
일관성이 지켜지지 않은 경우에는 모델이 서로 상충되는 데이터를 학습하여 혼란이 가중될 수 있습니다. 또한, 편향된 결과를 초래도출하거나 일반화 성능이 저하될 수 있습니다.
정확성
| 세부 품질 기준 | 품질 기준 설명 | 활용 예시 |
| 선후관계 정확성 | 여러 컬럼의 값이 선후관계에 잇으면 관련 규칙을 지킴 | 시작일은 종료일 이전 시점에 존재 |
| 계산/집계 정확성 | 특정 컬럼의 값이 여러 컬럼의 계산된 값이면 그 계산 결과가 정확해야 함 | 월 매출액은 일 매출액의 총합과 일치 |
| 최신성 | 정보 수집, 갱신 주기를 유지 | 고객의 현재 주소 데이터는 마지막으로 이사한 곳의 주소와 동일 |
정확성이 지켜지지 않은 경우에는 모델이 잘못된 패턴을 학습하여 신뢰성이 떨어지는 결과를 출력할 수 있고, 윤리적 혹은 법적 문제가 발생할 수 있습니다.
적시성
- 주식 예측 모델 등 경우에 따라 데이터의 최신 정보가 필요할 수 있습니다.
- 만약 데이터가 오래되어 최신 정보를 반영하지 못하면, 현재에 맞지 않는 부정확한 결과를 출력할 수 있습니다.
최소 품질의 기준
데이터의 양이 많을 경우 모든 품질 기준 항목을 완벽하게 맞추기는 불가능에 가깝습니다. 따라서 비율을 정해 최소 품질 달성 기준을 설정하는 것도 좋은 방법입니다.
예시 기준
| 항목 | 최소 기준 | 검토 방법 |
| 완전성 | 결과 값 비율 < 5% | 결측 값 탐지 및 비율 계산 |
| 유효성 | 데이터 규칙 위반 < 5% | 정규식 포맷 검증 |
| 정확성 | 참조 데이터와 일치율 > 90% | 정규식 및 포맷 검증외부 데이터 소스와 비교 |
| 유일성 | 중복 값 비율 < 5% | 고유 식별 필드 설정 및 검증 |
| 일관성 | 데이터 간 불일치율 < 3% | 데이터베이스 참조 무결성 검증 |
비정형 데이터의 품질
이미지, 동영상, 오디오 등 정형화되지 않은 데이터는 각 데이터 유형 별로 품질 기준을 정의하는 것이 모두 다릅니다.
이미지 데이터
| 품질 기준 | 품질 기준 설명 | 활용 예시 |
| 해상도 | 이미지의 픽셀 수 | 고해상도 이미지를 위해 QHD 이상의 해상도만 채택 |
| 사용성 | 사용자에게 친숙하고 사용이 용이한 포맷 | jpg, png 포맷만 사용 (tif, dng 등은 친숙하지 않음) |
| 선명도 | 이미지 내 경계의 선명함의 정도 | Laplacian Variance 알고리즘 적용하여 측정 |
| 이해성 | 이미지가 정보를 명확히 전달하는 정도 | AI 모델이 이미지를 인식하는 정확도가 90% 이상인 데이터만 채택 |
오디오 데이터
| 품질 기준 | 품질 기준 설명 | 활용 예시 |
| 잡음비 | 유용 신호와 배경 노이즈 비율 측정 | SNR(신호 대 잡음비) 10dB 이하(통화 녹음 정도의 음질) 데이터만 선정 |
| 동적 범위 | 가장 큰 소리와 작은 소리의 범위 | Dynamic Range 60~90dB (일반적인 대화 정도의 소음) |
| 길이 일관성 | 재생 시간 길이의 일관성 | 55~65초 범위의 오디오 |
| 주파수 범위 | 특정 주파수 범위 포함 여부 | 사람이 들을 수 잇는 소리 기준은 20Hz ~ 20kHz 범위 내 주파수 포함 |
나쁜 데이터(저품질 데이터)
| 품질 기준 | 내용 |
| 완전성 | 데이터 누락 및 결측 치 존재 |
| 유일성 | 중복 데이터 존재 |
| 유효성 | 범위를 벗어나거나 정의와 맞지 않는 값 |
| 일관성 | 단위 불일치 등 비일관적인 형식과 구조 |
| 정확성 | 잘못된 정보가 있음 |
이러한 나쁜 데이터는 AI 모델 학습에 악영향을 미칩니다.
저품질 데이터가 AI 모델에 미치는 영향
라벨링이 잘못된 데이터는 AI에게 혼동을 주고, 이러한 데이터로 학습시키면 이미지 분류 성능이 매우 떨어집니다.
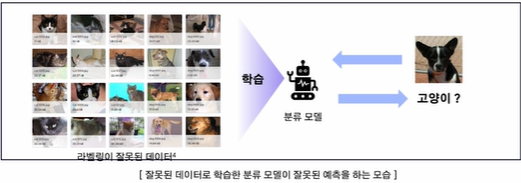
또한, 편향된 데이터에 의한 편향이 발생하고, 신뢰도와 공정성이 떨어질 수 있습니다.

'컴퓨터 과학(CS) > AI' 카테고리의 다른 글
| MCP(Model Context Protocol) (0) | 2025.11.04 |
|---|---|
| Large Language Models (0) | 2025.10.21 |
| 데이터 품질 관리 (2) | 2025.10.20 |
| Model-Centric AI, Data-Centric AI (0) | 2025.10.20 |
| 데이터와 AI 모델의 관계 (0) | 2025.10.20 |
