https://www.yes24.com/Product/Goods/84909414
임베디드 OS 개발 프로젝트 - 예스24
나만의 임베디드 운영체제를 만들어 보자.이 책은 펌웨어 개발 과정을 실시간 운영체제(RTOS)를 만들어 가며 설명한다. 임베디드 운영체제를 개발 환경 구성에서 시작해 최종적으로 RTOS를 만드는
www.yes24.com
공부 목적으로 이만우님의 저서 "임베디드 OS 개발 프로젝트"를 따라가며, RTOS "Navilos"를 개발하는 포스트입니다. 모든 내용은 "임베디드 OS 개발 프로젝트"에 포함되어 있습니다.
개발 목적
임베디드 시스템에 많이 사용되는 RTOS를 직접 개발해 보며 다음과 같은 지식을 학습하고자 합니다.
- RTOS의 핵심 개념에 대해 학습한다.
- 운영체제 핵심 기능을 설계해 보며 학습한다.
- 펌웨어에 대한 진입장벽을 낮춘다.
- ARM 아키텍처에 대해 학습한다.
- 하드웨어에 대한 지식을 학습한다.(펌웨어가 어떻게 하드웨어를 제어하는지)
이번 챕터에선 동기화를 공부하겠습니다.
나빌로스에서는 비선점형 스케줄링을 사용하는데다 명시적으로 Kernel_yield()를 호출해야 다른 태스크로 컨텍스트가 넘어가므로 싱글코어 환경에서는 동기화 문제가 발생하지 않습니다. 하지만 동기화라는 주제가 운영체제에서 매우 중요한 부분이므로 다뤄 보겠습니다.
동기화라는 용어는 운영체제에서 어떤 작업을 아토믹 오퍼레이션으로 만들어준다는 의미입니다.
어떤 작업이 아토믹하다는 것은 해당 작업이 끝날 때까지 컨텍스트 스위칭이 발생하지 않는다는 말입니다. 멀티코어 환경에서는 아토믹 동작이 진행 중일때 다른 코어가 해당 동작에 끼어들지 못하게 하는 것을 의미합니다.
어떤 작업이 아토믹하게 구현되어야 한다면 해당 작업을 크리티컬 섹션이라고 부릅니다.
다시 정리하자면, 동기화란 어떤 작업이 크리티컬 섹션이라고 판단될 경우, 해당 크리티컬 섹션을 아토믹 오퍼레이션으로 만들어주는 것을 말합니다.
동기화 알고리즘엔 여러 종류가 있는데, 가장 많이 쓰이는 세 가지를 구현해보겠습니다.
가장 많이 쓰이는 순서로 구현하겠습니다.
1. 세마포어(가장 많이 쓰임)
2. 뮤텍스
3. 스핀락
세마포어
동기화 알고리즘 중 가장 유명하면서 많이 쓰이는 알고리즘입니다. 1962년에 에츠허르 다익스트라가 발표한 논문에도 개념이 소개되었다고 합니다. 나온지 50년이 넘은 알고라즘입니다.
세마포어의 의사 코드(pseudo code)는 다음과 같습니다.
Test(s){
while S <= 0; // 대기
S--;
}
Release(S){
s++;
}
퍄 세마포어는 간단한 함수 Test(), Release() 두 개로 구현됩니다.
Test()함수는 이름 그대로 크리티컬 섹션에 진입 가능한지를 확인하는 함수입니다. 다른 의미로는 세마포어를 잠글(lock)할 수 있는지 확인하는 의미도 갖고 있습니다.
Release()는 크리티컬 섹션을 나갈 때 호출해서 세마포어를 놓아주는(release) 혹은 세마포어의 잠금을 푸는(unlock) 역할을 합니다.
여기서 동기화를 구현하는 두 가지 중요한 개념이 나옵니다. 바로 잠금과 잠금 해제입니다. 즉, 크리티컬 섹션의 진입할 때 잠그고, 나올때 잠금을 푸는 것입니다. 잠겨있는 도중에는 컨텍스트 스위칭도 발생하지 않고 다른 코어가 끼어들지도 못 합니다.
이제 세마포어를 구현해보겠습니다. kernel 디렉터리 하위에 synch.h와 synch.c를 만들겠습니다.
//synch.h
#ifndef KERNEL_SYNCH_H_
#define KERNEL_SYNCH_H_
void Kernel_sem_init(int32_t max);
bool Kernel_sem_test(void);
void Kernel_sem_release(void);
#endif /* KERNEL_SYNCH_H_ */
//synch.c
#include "stdint.h"
#include "stdbool.h"
#include "synch.h"
#define DEF_SEM_MAX 8
static int32_t sSemMax;
static int32_t sSem;
void Kernel_sem_init(int32_t max)
{
sSemMax = (max <= 0) ? DEF_SEM_MAX : max;
sSem = sSemMax;
}
bool Kernel_sem_test(void)
{
if (sSem <= 0)
{
return false;
}
sSem--;
return true;
}
void Kernel_sem_release(void)
{
if (sSem >= sSemMax)
{
sSem = sSemMax;
}
sSem++;
}
정해놓은 최댓값을 넘지 않도록 조정하는 코드가 추가된 것을 제외하면 의사 코드와 동일합니다.
Kernel_sem_init()은 세마포어 초기화 함수인데, max 파라미터로 세마포어의 최댓값을 받습니다. 예를들어 max가 1이면 크리티컬 섹션에는 컨텍스트가 딱 한 개만 진입할 수 있습니다. 이런 세마포어를 바이너리 세마포어라고 부릅니다. 당연히 이 값이 2면 컨텍스트 두 개, 3이면 컨텍스트 세 개까지 진입 가능합니다.
맨 위에 DEF_SEM_MAX를 8로 지정했기 때문에 나빌로스에서는 세마포어를 1부터 8까지 지정가능합니다.
세마포어는 커널 API를 통해 사용합니다. 그래서 Kernel.c 파일을 수정해서 세마포어용 커널 API를 구현하겠습니다.
//Kernel.c에 API 추가
void Kernel_lock_sem(void)
{
while(false == Kernel_sem_test())
{
Kernel_yield();
}
}
void Kernel_unlock_sem(void)
{
Kernel_sem_release();
}
좀 더 이해하기 쉽도록 lock, unlock으로 이름을 바꿨습니다.
의사 코드에서 무한 루프로 대기하는 것을 Kernel_yield()를 호출해서 스케줄링하는 것으로 구현했습니다. 이렇게 해야만 해당 크리티컬 섹션의 잠금을 소유하고 있는 다른 태스크로 컨텍스트가 넘어가서 세마포어의 잠금을 풀어줄 수 있기 때문입니다.
여기까지 세마포어의 기능 구현은 모두 완료했습니다.
이제 테스트를 진행해야 하는데, QEMU의 RealViewPB는 싱글코어 에뮬레이터입니다. 게다가 나빌로스는 비선점형 스케줄러인데다 커널이 강제로 스케줄링하는 것이 아닌 태스크가 Kernel_yield()를 호출해야만 스케줄링이 동작하므로 동기화 문제를 발생시키기 어렵습니다.
그래서 테스트를 위해 억지로 이상한 코드를 작성하겠습니다.
//Uart.c X 키를 누를 때 CmdOut 이벤트 발생
static void interrupt_handler(void)
{
uint8_t ch = Hal_uart_get_char();
if (ch != 'X')
{
Hal_uart_put_char(ch);
Kernel_send_msg(KernelMsgQ_Task0, &ch, 1);
Kernel_send_events(KernelEventFlag_UartIn);
}
else
{
Kernel_send_events(KernelEventFlag_CmdOut);
}
}
//Main.c 억지로 만든 동기화 테스트 코드
static uint32_t shared_value;
static void Test_critical_section(uint32_t p, uint32_t taskId)
{
debug_printf("User Task #%u Send=%u\\n", taskId, p);
shared_value = p;
Kernel_yield();
delay(1000);
debug_printf("User Task #%u Shared Value=%u\\n", taskId, shared_value);
}
void User_task0(void)
{
uint32_t local = 0;
debug_printf("User Task #0 SP=0x%x\\n", &local);
uint8_t cmdBuf[16];
uint32_t cmdBufIdx = 0;
uint8_t uartch = 0;
while(true)
{
KernelEventFlag_t handle_event = Kernel_wait_events(KernelEventFlag_UartIn|KernelEventFlag_CmdOut);
switch(handle_event)
{
case KernelEventFlag_UartIn:
Kernel_recv_msg(KernelMsgQ_Task0, &uartch, 1);
if (uartch == '\\r')
{
cmdBuf[cmdBufIdx] = '\\0';
Kernel_send_msg(KernelMsgQ_Task1, &cmdBufIdx, 1);
Kernel_send_msg(KernelMsgQ_Task1, cmdBuf, cmdBufIdx);
Kernel_send_events(KernelEventFlag_CmdIn);
cmdBufIdx = 0;
}
else
{
cmdBuf[cmdBufIdx] = uartch;
cmdBufIdx++;
cmdBufIdx %= 16;
}
break;
case KernelEventFlag_CmdOut:
//debug_printf("\\nCmdOut Event by Task0\\n");
Test_critical_section(5, 0);
break;
}
Kernel_yield();
}
}
void User_task2(void)
{
uint32_t local = 0;
debug_printf("User Task #2 SP=0x%x\\n", &local);
while(true)
{
Test_critical_section(3, 2);
Kernel_yield();
}
}
테스트용 크리티컬 섹션 함수를 작성했습니다. 크리티컬 섹션을 만드려면 여러 태스크 혹은 여러 코어가 공유하는 공유 자원이 있어야 합니다. 이 공유 자원 역할을 하는 것이 shared_value라는 로컬 전역 변수입니다. 그리고 Test_critical_section()함수는 파라미터 두 개를 받습니다. 첫 번째 파라미터는 공유 자원의 값을 바꿀 입력 값이고, 두 번째 파라미터는 함수를 호출한 태스크의 번호입니다. 함수가 호출되면 태스크의 번호와 어떤 입력을 남겼는지 출력하고, 공유 변수의 값을 바꿉니다. 그리고 Kernel_yield()를 호출해서 억지로 스케줄링합니다. 그리고 마지막으로 태스크 번호와 공유 변수의 값을 출력합니다.
Task2에서 동시에 크리티컬 섹션에 접근하는 코드로 수정했습니다.
빌드 후 실행하면 다음과 같습니다.
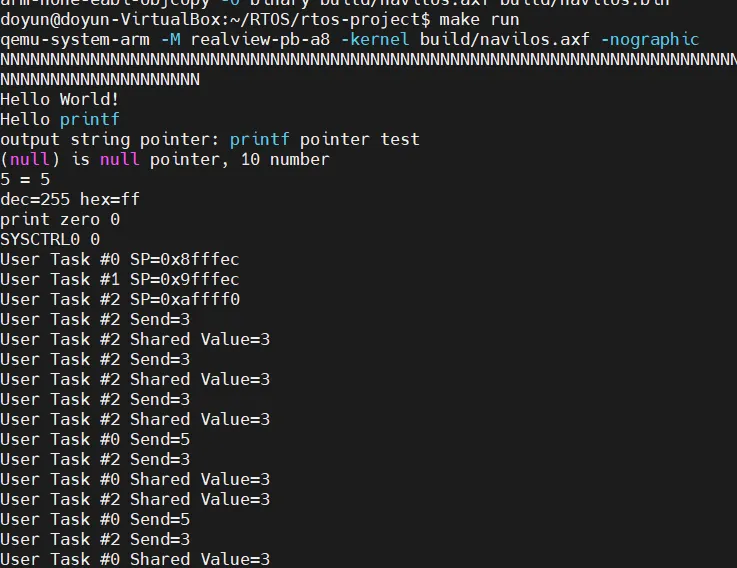
X를 입력하면 Task0이 실행되는데, Task0에서 3을 보냈다고 출력하는 부분이 가끔 보입니다. 원래는 5가 출려되어야 되는데 잘못된 결과입니다.
이제 세마포어를 적용하여 해결하겠습니다.
//Main.c 세마포어 추가
static void Kernel_init(void)
{
uint32_t taskId;
Kernel_task_init();
Kernel_event_flag_init();
Kernel_msgQ_init();
Kernel_sem_init(1);
...
static void Test_critical_section(uint32_t p, uint32_t taskId)
{
Kernel_lock_sem();
debug_printf("User Task #%u Send=%u\\n", taskId, p);
shared_value = p;
Kernel_yield();
delay(1000);
debug_printf("User Task #%u Shared Value=%u\\n", taskId, shared_value);
Kernel_unlock_sem();
}
Kernel_init()에서 Kernel_sem_init(1)을 해주었습니다. 이는 세마포어 잠금 개수를 1로 설정하는 것입니다. 즉, 바이너리 세마포어로 사용한다는 것입니다.
그리고 크리티컬 섹션의 시작과 끝에 세마포어 잠금, 잠금 해제를 해주었습니다.
이제 테스트를 해보면
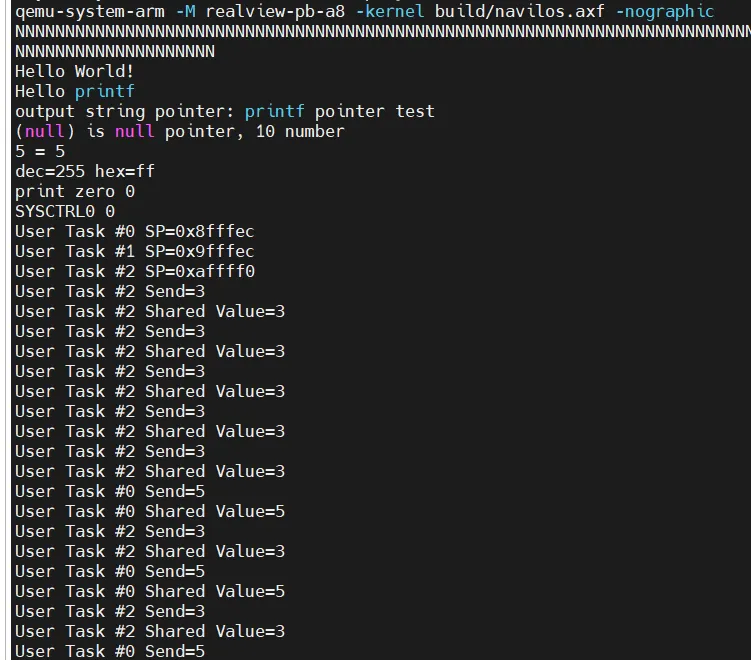
오류가 발생하지 않고 잘 동작하는 것을 볼 수 있습니다.
뮤텍스
또 다른 동기화 알고리즘으로 뮤텍스가 있습니다. 뮤텍스는 바이너리 세마포어의 일종입니다. 여기엔 특별한 점이 추가되었는데, 바로 소유의 개념입니다. 세마포어는 잠금에 대한 소유 개념이 없어서 누가 잠근 세마포어든 간에 누구나 잠금을 풀 수 있었습니다. 그러나 뮤텍스는 뮤텍스를 잠근 태스크만 뮤텍스 잠금을 해제할 수 있습니다.
즉, 뮤텍스는 바이너리 세마포어에 소유의 개념을 더한 동기화 알고리즘 입니다.
뮤텍스는 기존 세마포어를 만들었던 synch.c와 synch.h에 추가해서 구현하겠습니다.
//synch.h
#ifndef KERNEL_SYNCH_H_
#define KERNEL_SYNCH_H_
typedef struct KernelMutex_t{
uint32_t owner;
bool lock;
} KernelMutex_t;
void Kernel_sem_init(int32_t max);
bool Kernel_sem_test(void);
void Kernel_sem_release(void);
void Kernel_mutex_init(void);
bool Kernel_mutex_lock(uint32_t owner);
bool Kernel_mutex_unlock(uint32_t owner);
#endif /* KERNEL_SYNCH_H_ */
파라미터로 owner를 받는 것을 제외하면 세마포어와 동일합니다. 추가로 뮤텍스는 세마포어와 달리 별도의 자료 구조가 필요합니다. 뮤텍스 구조체에는 owner와 lock을 선언했는데, 뮤텍스의 소유자와 잠금을 표시하는 것입니다.
//syhch.c
#include "stdint.h"
#include "stdbool.h"
#include "synch.h"
#define DEF_SEM_MAX 8
static int32_t sSemMax;
static int32_t sSem;
KernelMutext_t sMutex;
void Kernel_sem_init(int32_t max)
{
sSemMax = (max <= 0) ? DEF_SEM_MAX : max;
sSemMax = (max >= DEF_SEM_MAX) ? DEF_SEM_MAX : max;
sSem = sSemMax;
}
bool Kernel_sem_test(void)
{
if (sSem <= 0)
{
return false;
}
sSem--;
return true;
}
void Kernel_sem_release(void)
{
sSem++;
if (sSem >= sSemMax)
{
sSem = sSemMax;
}
}
void Kernel_mutex_init(void)
{
sMutex.owner = 0;
sMutex.lock = false;
}
bool Kernel_mutex_lock(uint32_t owner)
{
if (sMutex.lock)
{
return false;
}
sMutex.owner = owner;
sMutex.lock = true;
return true;
}
bool Kernel_mutex_unlock(uint32_t owner)
{
if (owner == sMutex.owner)
{
sMutex.lock = false;
return true;
}
return false;
}
뮤텍스를 전역 변수로 선언했습니다.
구현을 단순하게 하기 위해 그냥 변수로 선언했는데, 필요에 따라 배열로 만들어 뮤텍스를 여러 개 사용할 수도 있습니다.
- Kernel_mutex_init()은 sMutex를 0으로 초기화하는 함수입니다.
이제 커널 API를 구현하겠습니다.
//Kernel.c에 API 추가
void Kernel_lock_mutex(void)
{
while(true)
{
uint32_t current_task_id = Kernel_task_get_current_task_id();
if (false == Kernel_mutex_lock(current_task_id))
{
Kernel_yield();
}
else
{
break;
}
}
}
void Kernel_unlock_mutex(void)
{
uint32_t current_task_id = Kernel_task_get_current_task_id();
if (false == Kernel_mutex_unlock(current_task_id))
{
Kernel_yield();
}
}
잠금할 때 뮤텍스의 소유자를 알려주는 것과 잠금이 해제되었는지 확인하는 내용만 제외하면 세마포어와 동일합니다. 잠금 해제도 마찬가지 입니다.
여기서 Kernel_task_get_current_task_id()란 함수는 처음 볼텐데 직접 구현해야 합니다.
//task.c
uint32_t Kernel_task_get_current_task_id(void)
{
return sCurrent_tcb_index;
}
이제 뮤텍스를 구현하는 코드는 모두 준비되었습니다. 이제 테스트를 할건데 우선 세마포어와 뮤텍스의 차이를 확인할 것입니다.
예제로 세마포어를 Task0에서 잠그고 Task1에서 잠금을 푸는 것을 해보겠습니다.
새로운 이벤트 unlock을 추가하겠습니다.
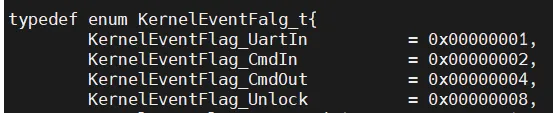
이제 Unlock 이벤트를 발생시키도록 UART 인터럽트 핸들러를 변경하겠습니다.
//Uart.c UART 인터럽트 핸들러 변경
static void interrupt_handler(void)
{
uint8_t ch = Hal_uart_get_char();
if (ch == 'U')
{
Kernel_send_events(KernelEventFlag_Unlock);
return;
}
if (ch == 'X')
{
Kernel_send_events(KernelEventFlag_CmdOut);
return;
}
Hal_uart_put_char(ch);
Kernel_send_msg(KernelMsgQ_Task0, &ch, 1);
Kernel_send_events(KernelEventFlag_UartIn);
}
U를 입력했을 때 Unlock 이벤트를 보냅니다.
이것은 테스트 용 Main.c입니다.
//Main.c
#include "stdint.h"
#include "stdbool.h"
#include "HalUart.h"
#include "HalInterrupt.h"
#include "HalTimer.h"
#include "stdio.h"
#include "stdlib.h"
#include "Kernel.h"
static void Hw_init(void);
static void Kernel_init(void);
static void Printf_test(void);
static void Timer_test(void);
static void Test_critical_section(uint32_t p, uint32_t taskId);
void User_task0(void);
void User_task1(void);
void User_task2(void);
void main(void)
{
Hw_init();
uint32_t i = 100;
while(i--)
{
Hal_uart_put_char('N');
}
Hal_uart_put_char('\n');
putstr("Hello World!\n");
Printf_test();
Timer_test();
Kernel_init();
while(true);
}
static void Hw_init(void)
{
Hal_interrupt_init();
Hal_uart_init();
Hal_timer_init();
}
static void Kernel_init(void)
{
uint32_t taskId;
Kernel_task_init();
Kernel_event_flag_init();
Kernel_msgQ_init();
Kernel_sem_init(1);
Kernel_mutex_init();
taskId = Kernel_task_create(User_task0);
if (NOT_ENOUGH_TASK_NUM == taskId)
{
putstr("Task0 creation fail\n");
}
taskId = Kernel_task_create(User_task1);
if (NOT_ENOUGH_TASK_NUM == taskId)
{
putstr("Task1 creation fail\n");
}
taskId = Kernel_task_create(User_task2);
if (NOT_ENOUGH_TASK_NUM == taskId)
{
putstr("Task2 creation fail\n");
}
Kernel_start();
}
static void Printf_test(void)
{
char* str = "printf pointer test";
char* nullptr = 0;
uint32_t i = 5;
uint32_t* sysctrl0 = (uint32_t*)0x10001000;
debug_printf("%s\n", "Hello printf");
debug_printf("output string pointer: %s\n", str);
debug_printf("%s is null pointer, %u number\n", nullptr, 10);
debug_printf("%u = 5\n", i);
debug_printf("dec=%u hex=%x\n", 0xff, 0xff);
debug_printf("print zero %u\n", 0);
debug_printf("SYSCTRL0 %x\n", *sysctrl0);
}
static void Timer_test(void)
{
for(uint32_t i = 0; i < 5 ; i++)
{
debug_printf("current count : %u\n", Hal_timer_get_1ms_counter());
delay(1000);
}
}
void User_task0(void)
{
uint32_t local = 0;
debug_printf("User Task #0 SP=0x%x\n", &local);
uint8_t cmdBuf[16];
uint32_t cmdBufIdx = 0;
uint8_t uartch = 0;
while(true)
{
KernelEventFlag_t handle_event = Kernel_wait_events(KernelEventFlag_UartIn|KernelEventFlag_CmdOut);
switch(handle_event)
{
case KernelEventFlag_UartIn:
Kernel_recv_msg(KernelMsgQ_Task0, &uartch, 1);
if (uartch == '\r')
{
cmdBuf[cmdBufIdx] = '\0';
Kernel_send_msg(KernelMsgQ_Task1, &cmdBufIdx, 1);
Kernel_send_msg(KernelMsgQ_Task1, cmdBuf, cmdBufIdx);
Kernel_send_events(KernelEventFlag_CmdIn);
cmdBufIdx = 0;
}
else
{
cmdBuf[cmdBufIdx] = uartch;
cmdBufIdx++;
cmdBufIdx %= 16;
}
break;
case KernelEventFlag_CmdOut:
//debug_printf("\nCmdOut Event by Task0\n");
Test_critical_section(5, 0);
break;
}
Kernel_yield();
}
}
void User_task1(void)
{
uint32_t local = 0;
debug_printf("User Task #1 SP=0x%x\n", &local);
uint8_t cmdlen = 0;
uint8_t cmd[16] = {0};
while(true)
{
KernelEventFlag_t handle_event = Kernel_wait_events(KernelEventFlag_CmdIn|KernelEventFlag_Unlock);
switch(handle_event)
{
case KernelEventFlag_CmdIn:
memclr(cmd, 16);
Kernel_recv_msg(KernelMsgQ_Task1, &cmdlen, 1);
Kernel_recv_msg(KernelMsgQ_Task1, cmd, cmdlen);
debug_printf("\nRecv Cmd: %s\n", cmd);
break;
case KernelEventFlag_Unlock:
break;
}
Kernel_yield();
}
}
void User_task2(void)
{
uint32_t local = 0;
debug_printf("User Task #2 SP=0x%x\n", &local);
while(true)
{
Test_critical_section(3, 2);
Kernel_yield();
}
}
static uint32_t shared_value;
static void Test_critical_section(uint32_t p, uint32_t taskId)
{
Kernel_lock_mutex();
debug_printf("User Task #%u Send=%u\n", taskId, p);
shared_value = p;
Kernel_yield();
delay(1000);
debug_printf("User Task #%u Shared Value=%u\n", taskId, shared_value);
Kernel_unlock_mutex();
}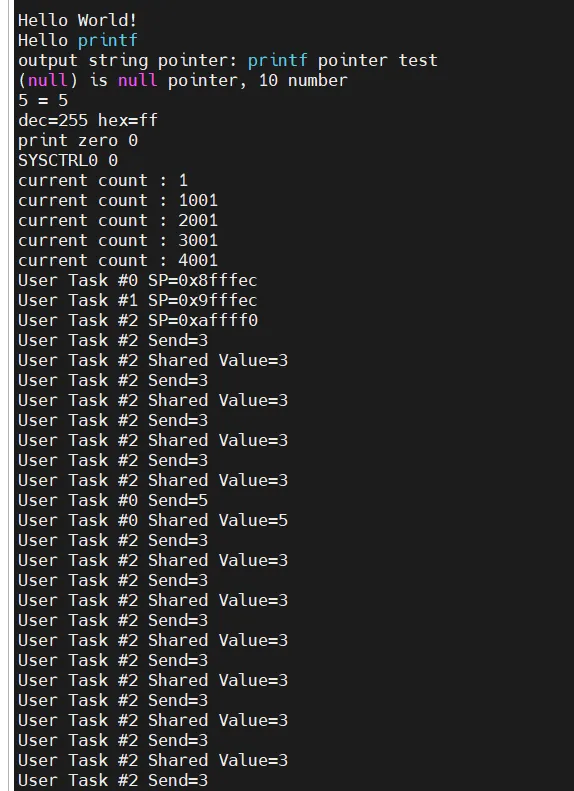
테스트 해보니 value가 task2는 value 3, task0일땐 value 5가 제대로 값이 출력되는 것을 확인할 수 있었습니다.
스핀락
스핀락은 바쁜 대기 개념의 크리티컬 섹션 보호 기능입니다.
바쁜 대기란 스케줄링을 하지 않고 CPU를 점유한 상태, 즉 CPU가 바쁜 상태에서 락이 풀리는 것을 기다리는 것을 대기한다는 말입니다. 싱글코어 환경에서는 다른 태스크가 잠금을 풀려면 어차피 스케줄링을 해야 하므로 스핀락을 사용할 수 없습니다.
실제 스핀락 구현은 바쁜 대기 자체가 완전히 아토믹해야 하기 때문에 배타적 메모리 연산을 지원하는 어셈블리어 명령으로 구현됩니다만 이 책에서는 개념 설명이 우선이므로 C언어 코드로 의사 코드를 작성하겠습니다. 코드를 이해할 때는 해당 함수가 아토믹하게 동작한다고 생각해 주길 바랍니다.
의사 코드로 표현한 스핀락의 기본 구현입니다.
static bool sSpinLock = false;
void spin_lock(void){
while (sSpinlock); // 대기
sSpinLock = true; // 잠금
}
void spin_unlock(void){
sSpinLock = false; // 해제
}
스핀락 변수가 불타입이라 바이너리 세마포어와 같은 동작을 합니다.
그리고 대기할 때 스케줄러를 호출하지 않고 그냥 while문에서 CPU를 점유한 채로 대기합니다.
→ 다른 코어에서 동작 중인 스핀락을 잠갔던 태스크가 spin_unlock() 함수를 호출하면 공유 변수인 sSpinLock 변수를 false로 바꿔 while문에 대기가 풀리면서 크리티컬 섹션에 진입하게 됩니다.
마치며
이번 챕터에선 동기화 기능을 만들었습니다. 나빌로스는 설계상 싱글코어 환경에서는 동기화 문제가 발생하지는 않습니다.
하지만, 동기화의 개념은 중요하기에 실습을 진행한 것입니다. 동기화의 개념을 이해하고 있으면 실제 필요한 상황에 직면했을 때 문제를 쉽게 해결할 수 있을 것입니다.
참고
RealViewPB 데이터시트 https://developer.arm.com/documentation/dui0417/d/?lang=en
Documentation – Arm Developer
developer.arm.com
저자 이만우님 깃허브 https://github.com/navilera/Navilos
GitHub - navilera/Navilos: RTOS for various embedded platform
RTOS for various embedded platform. Contribute to navilera/Navilos development by creating an account on GitHub.
github.com
'임베디드' 카테고리의 다른 글
| [RTOS 개발하기] 임베디드 개발 프로젝트 후기 (1) | 2024.12.02 |
|---|---|
| Arm 아키텍처 (1) | 2024.12.02 |
| [RTOS 개발하기] 임베디드 OS 개발 프로젝트ch.12 (0) | 2024.11.18 |
| [RTOS 개발하기] 임베디드 OS 개발 프로젝트ch.11 (1) | 2024.11.16 |
| [RTOS 개발하기] 임베디드 OS 개발 프로젝트ch.10 (0) | 2024.11.13 |

